Register Any Point:
Scaling 3D Point Cloud Registration by Flow Matching
Accomplish single-stage multi-view point cloud registration at various scales by flow matching-based generation
Overview
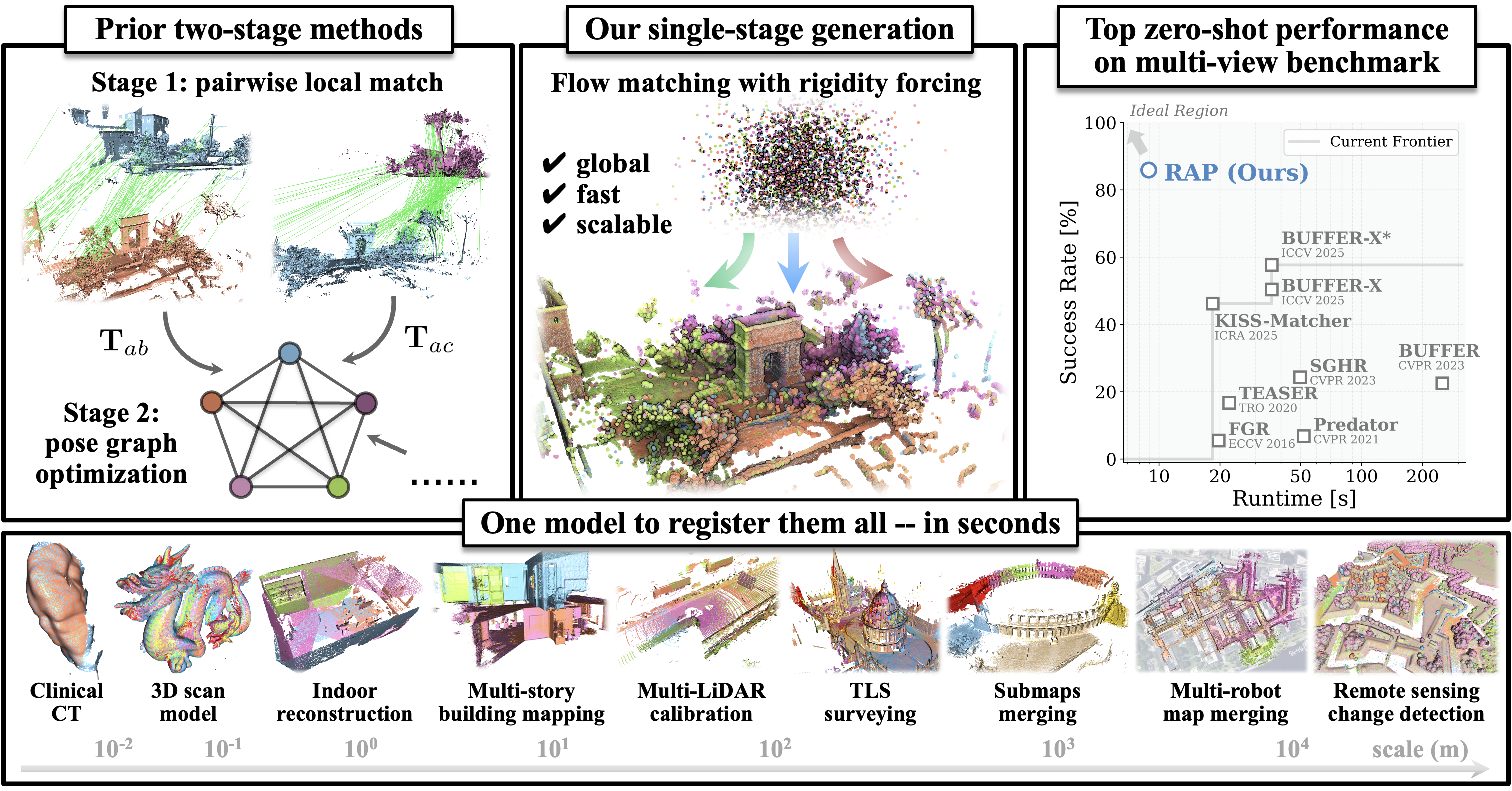
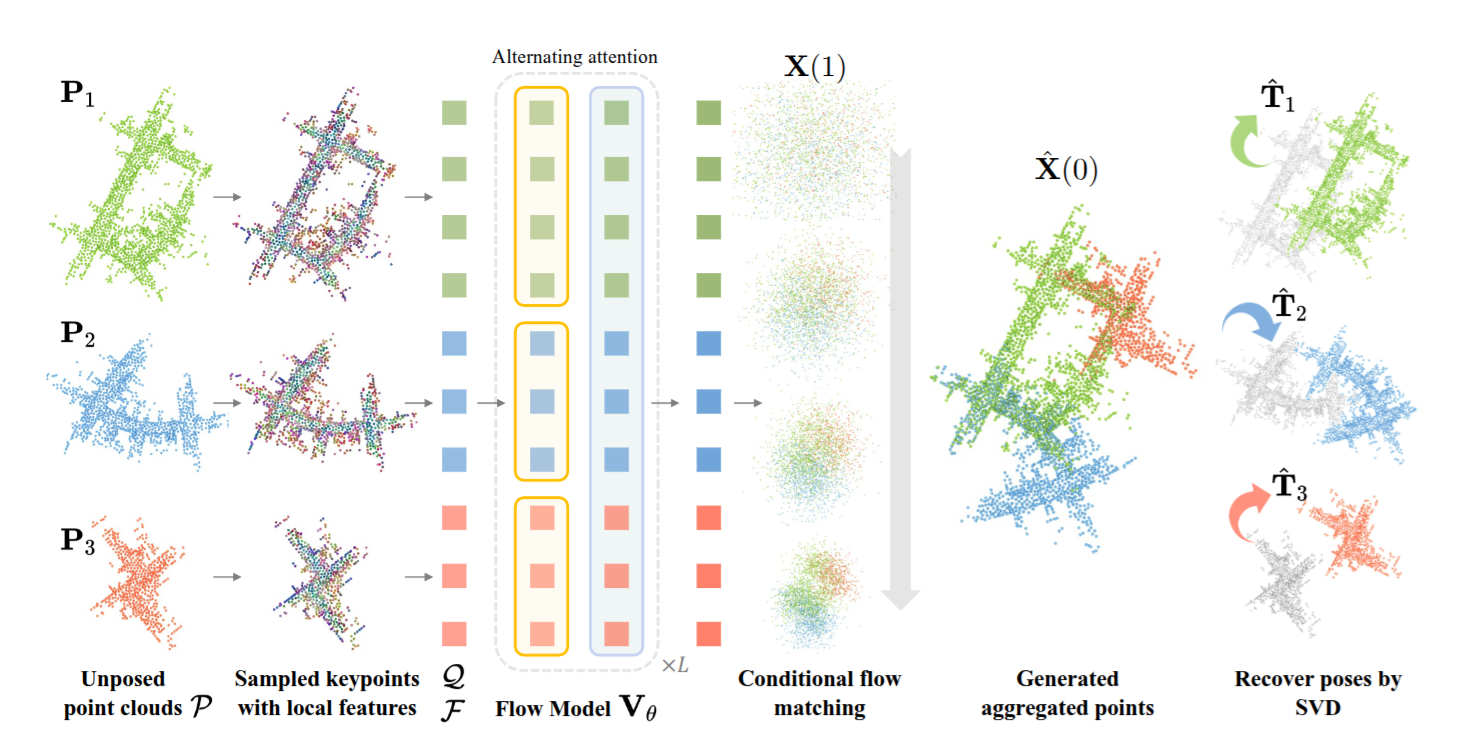
Our method for scalable multi-view point cloud registration. To register multiple unposed point clouds, prior work typically first performs correspondence matching and then optimizes a pose graph (top-left). In contrast, we introduce a single-stage model that directly generates the registered point cloud via flow matching in Euclidean space (top-right), bypassing the need for explicit correspondence matching and pose graph optimization. Our model generalizes across diverse point cloud data from object-centric, indoor, and outdoor scenarios at scan, sub-map, and map levels (bottom).
Acknowledgments
This work is built upon Rectified Point Flow. We also thank the authors of the following works: BUFFER-X and GARF.